集計クエリにおけるデータの抽出には、「HAVING句」を使った方法と「WHERE句」を使った方法の2通りの条件指定方法があります。Accessのクエリのデザインビューにおいては、通常の選択クエリと同じような感覚で抽出条件を指定すると自動的にHAVING句になってしまいますが、意図的に抽出条件となるフィールドをグリッドに追加し、「集計」欄を"Where 条件"にすることでWHERE句にすることができます。もちろんSQLビューであればそれらの句を明示的に記述することもできます。
HAVING句は、グループ集計した結果に対して抽出条件を指定するものです。例えば、商品ごとの合計受注金額を集計クエリによって求め、その金額が一定額以上のデータだけを抽出するような場合、合計受注金額はグループ集計を行ったあとに得られますので、その抽出条件は、そのフィールドにHAVING句を記述することによって指定します。集計結果に対して抽出を行うこのケースでは、WHERE句は使えません。
一方、ある抽出条件を満たす商品だけの合計受注金額を集計クエリによって求める場合、1つには、上記と同様にHAVING句を使う方法があります。 この場合、"商品コード"といったようなフィールドに対して"グループ化"を指定するはずですが、集計クエリの結果には一連の商品コードが並ぶことになりますので、それに対して抽出条件を指定することになります。もう1つはあらかじめWHERE句として抽出条件を指定する方法です。この場合は、論理的にはまず該当する商品のレコードだけを抽出して、そのあとそれらの範囲だけで集計を行うことになります。つまり、いずれの方法も集計クエリの結果として導き出されるレコードは同一のものとなりますが、集計してから抽出するか、あるいは抽出してから集計するかの内部的な手順に違いが出てきます。当然、テーブルのレコード数が膨大である場合、全レコードについて集計演算してから抽出するのと、あらかじめ対象レコードを絞り込んだ状態で集計演算を掛けるのとでは、処理時間にも違いが出てくるはずです。事実、他のデータベースエンジン(具体的にはMySQL)においては、その違いが処理時間に非常に顕著に現れるケースもあります。WHERE句を使った方が断然短時間で処理されることがあるのです。ところがAccessのクエリデザインビューではマウス操作で簡単にクエリが作れてしまいますし、どちらも同じデータ結果となるため、両者をあまり(あるいは全然)意識する必要がありません。そこで、実際にAccessでそれを意識してクエリの抽出条件の指定方法を使い分けたとき、どれだけのパフォーマンスの違いがあるのかを今回テストしてみたいと思います。
まず、テスト用のテーブルとして、10万件の受注明細データが入ったテーブルを用意します。参考までに、このテーブルに対して以下で説明する集計クエリを実行した場合、抽出条件が皆無のときは5000レコードにデータがグループ化され集約されます。また下図の抽出条件の場合には1000レコードに集約されるテストデータとなっています。
また、そのテーブルに対して、商品ごとの合計数量や合計金額を集計するクエリを作成します。さらにここでは「商品コード」に対して抽出条件を指定するものとします。
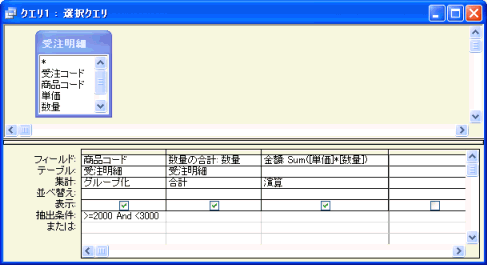
1つのクエリはHAVING句を使ったものです。下図のように、"グループ化"された「商品コード」フィールドの抽出条件の欄にその条件式を入力します。
これはSQLでは次のようになります。

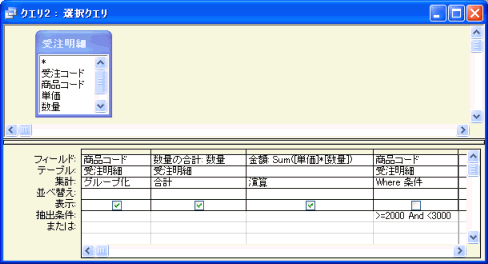
もう1つのクエリはWHERE句を使ったものです。下図のように、"グループ化"する「商品コード」とは別にもう1つ、"Where 条件"とする「商品コード」フィールドをグリッドに配置し、その抽出条件の欄の方に条件式を入力します。
これはSQLでは次のようになります。

クエリの準備ができたところで、実際にそれらのクエリを開いてその処理時間を測定するためのテスト用プログラムを作成します。ここでは、次のようなコードを用います。処理としては非常にシンプルなもので、クエリを開いたらその最終レコードに一気にジャンプして閉じる、という処理を100回繰り返すものです。
Dim dbs As Database
Dim rst As Recordset
Dim iintLoop As Integer
ts_Watch "処理開始", True
Set dbs = CurrentDb
For iintLoop = 1 To 100
Set rst = dbs.OpenRecordset("クエリ1")
rst.MoveLast
rst.Close
ts_Watch "HAVING"
Set rst = dbs.OpenRecordset("クエリ2")
rst.MoveLast
rst.Close
ts_Watch "WHERE"
Next iintLoop
テストとしては上記のコードを実行するだけです。その結果は次のようなものになりました。いずれも単位は秒です。
ご覧のように、厳密にはむしろWHERE句の方が時間がかかっていますが、おおむねの結論としては、「どちらもまったく同じ」と考えてよいでしょう。
合計 平均 最大 最小 HAVING句 27.34 0.27 0.34 0.27 WHERE句 27.63 0.28 0.33 0.27
このことから、データベースエンジンによってはHAVING句とWHERE句の違いは非常に大きなものがありますが、AccessのJETデータベースエンジンに関してはあまりそれは関係ないといえるようです。今回テストで用いたテーブルには10万件のレコードが保存されていますが、現実的にはAccessを使う範疇ではけっして少なめのデータ件数とはいえないと思います。ということは、実用的な範疇でのAccessではHAVING句とWHERE句をまったく意識しなくてよいと結論付けてもよいでしょう。
JETデータベースエンジンの内部構造、あるいはAccessクエリの内部的な文法解釈や実行手順を図り知ることはできませんが、おそらくHAVING句とWHERE句の違い、つまり、集計してから抽出するか、あるいは抽出してから集計するかの内部的な手順の違いはまったく差がない結果となるように、いずれかの内部手順の段階で調節れているのではないかと思われます。例えば、HAVING句を使ってもWHERE句を使っても結果が同じ場合には、まず抽出してから集計するよう勝手にSQLの解釈・実行手順を変更して処理されているのかもしれません。この点はまったく推測の域を出ませんが、Accessが簡便に出来ているということは確かに言えると思います。ただし、この"違いの無さ"はすべてのデータベースエンジンに当てはまるものではないことも確かです。データベースエンジンによってはHAVING句とWHERE句は大きく処理時間が変わるケースもあることも知っておくとよいかもしれません。