Recordsetオブジェクトの GetRowsメソッド は、Recordset内のフィールドデータを高速に取り出す方法としてしばしば取り上げられる手法です。GetRowsメソッドは1回の呼び出しでテーブルやクエリー内の全レコード・全フィールドを2次元の配列(1つ目の添字がフィールドを示し、2つ目の添字がレコード番号を示す)として取り出してくれるもので、後でそのデータを扱う際にフィールドを固有の名前ではなく配列の添字で扱わなければならないという不便さはありますが、Do〜Loopなどの複数行のコードを記述しなくて済みますし、複数のレコードにまたがっていろいろな計算をするような場合や連続するフィールドに対して同じ計算を繰り返すような場合には、添字をループで処理することによってコードが簡単になる場合もあり、何かと便利なメソッドです。
そこでここでは、取得したデータの扱い方のメリット・デメリットはさておき、一般に言われるレコード読み込みの高速化のメリットは定量的にはどの程度あるのか、実際に時間を測定して検証してみたいと思います。
また、GetRowsメソッドは取得した全レコード・全フィールドを一度に配列に格納しますので、当然レコード数が多ければ大量のメモリを消費することになります。そのため、GetRowsメソッドを使う際の注意事項として「大きなテーブルの全体を配列に格納するべきではない」とされていますが、実際に何千件ものレコードを読み込ませたらどうなるのか、パフォーマンスが低下するのか?、メモリ上の何らかのトラブルが発生するのか?、これについても試してみたいと思います。
まず、今回のテスト内容を整理してみました。
■読み込むテーブル(入出庫情報1〜5)のフィールド構成
フィールド名 データ型 フィールドサイズ 配列格納時の
メモリサイズ(※注)入出庫ID オートナンバー型 4 16 発生日 日付/時刻型 8 16 商品ID 長整数型 4 16 発注伝票ID 長整数型 4 16 処理内容 テキスト型 255 277 単価 通貨型 8 16 発注数 長整数型 4 16 入庫数 長整数型 4 16 出庫数 長整数型 4 16 返品数 長整数型 4 16 1レコード当たりの合計 421バイト ※注 GetRowsメソッドでは、取得したデータはフィールドのデータ型に関係なくすべてバリアント型の配列に格納されます。バリアント型では、数値は 16バイト、文字列は 22バイト+文字列の長さ のサイズとなります。
■テストパターン
読込レコード数 配列のサイズ
(421バイト×レコード数)100 41Kバイト 500 206 Kバイト 1000 411 Kバイト 5000 2,056 Kバイト 10000 4,111 Kバイト
■テスト項目の2つについて、上記5通りのテストパターンを実行します。1については「#12 ループ内ではフィールドを参照しない方がよい?」のテストで処理が速いとされた[Field]オブジェクトを使った方法で試してみます。
- 全レコードに対してループを使ってテーブルのデータを取得する方法
- GetRowsメソッドを使って一度にテーブルのデータを取得する方法
テストコードは次のようなものです。
Dim dbs As Database
Dim rst As Recordset
Dim intRecCnt As Integer
Dim varRecords As Variant
Dim intRLoop As Integer
Dim intCLoop As Integer
Dim varTemp As Variant
Dim fld1 As Field, fld2 As Field, fld3 As Field, fld4 As Field, fld5 As Field
Dim fld6 As Field, fld7 As Field, fld8 As Field, fld9 As Field, fld10 As Field
'このテーブル名の定数値をテストパターンごとに変えます
Const cstrTestTable As String = "入出庫情報1"
ts_watch "テスト開始", True
'ループを使った読み込み
Set dbs = CurrentDb
Set rst = dbs.OpenRecordset(cstrTestTable)
With rst
'レコードセットのレコード数を取得するためレコード移動
.MoveLast: .MoveFirst
intRecCnt = .RecordCount
'各Fieldオブジェクトをセット
Set fld1 = .Fields!入出庫ID
Set fld2 = .Fields!発生日
Set fld3 = .Fields!商品ID
Set fld4 = .Fields!発注伝票ID
Set fld5 = .Fields!処理内容
Set fld6 = .Fields!単価
Set fld7 = .Fields!発注数
Set fld8 = .Fields!入庫数
Set fld9 = .Fields!出庫数
Set fld10 = .Fields!返品数
'全レコードのループ
For intRLoop = 1 To intRecCnt
'カレントレコードのFieldオブジェクトを仮の変数にセット
varTemp = fld1
varTemp = fld2
varTemp = fld3
varTemp = fld4
varTemp = fld5
varTemp = fld6
varTemp = fld7
varTemp = fld8
varTemp = fld9
varTemp = fld10
.MoveNext
Next intRLoop
.Close
End With
dbs.Close
ts_watch "ループでの読み込み"
'GetRowsメソッドを使った読み込み
Set dbs = CurrentDb
Set rst = dbs.OpenRecordset(cstrTestTable)
'レコードセットのレコード数を取得するためレコード移動
rst.MoveLast: rst.MoveFirst
intRecCnt = rst.RecordCount
'すべてのレコードを配列にセット
varRecords = rst.GetRows(intRecCnt)
'行方向(レコード)のループ
For intRLoop = 0 To UBound(varRecords, 2)
'列方向(フィールド)のループ
For intCLoop = 0 To UBound(varRecords, 1)
'配列の各データを仮の変数にセット
varTemp = varRecords(intCLoop, intRLoop)
Next intCLoop
Next intRLoop
rst.Close
dbs.Close
ts_watch "GetRowsでの読み込み"
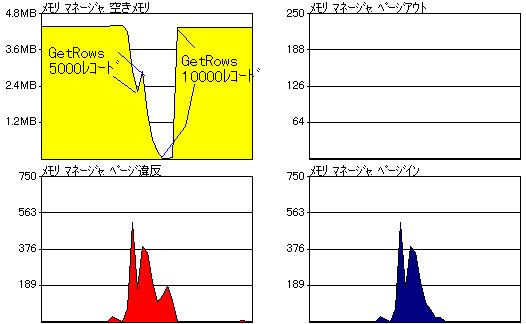
そして、テスト結果は次のようになりました。合わせて、テスト中のメモリの状態をチェックするために起動しておいたシステムモニターのグラフも示します。
レコード数 配列のサイズ ループを使った場合
の読込時間(Sec)GetRowsを使った場合
の読込時間(Sec)100 41Kバイト 0.08 0.09 500 206 Kバイト 0.17 0.15 1000 411 Kバイト 0.29 0.28 5000 2,056 Kバイト 1.25 2.16 10000 4,111 Kバイト 2.50 6.83
100〜1000レコードのテスト結果を見る限りでは GetRowsメソッドを使うことによる時間的なメリットはあまりないように見えます。しかし、「#12 ループ内ではフィールドを参照しない方がよい?」のテスト結果も合わせて考えてみると、Fieldオブジェクトを使った方法自体が毎回Recordsetオブジェクト上のフィールドを直接参照する方法に比べて相当高速なわけですから、テーブルのレコードにアクセスするさまざまな方法全体から見ればやはりGetRowsメソッドはかなり速いと言ってよいでしょう。また、Fieldオブジェクトを使うかGetRowsメソッドを使うかの判断では、このレコード数の範囲では時間的にはほとんど違いはありませんので、コードの記述のシンプルさや、各レコード・フィールドを固有のフィールド名称ではなく配列の行列として扱えるという利便性が必要とされる場面ではGetRowsメソッドを使えばよいでしょう。
一方、5000〜10000レコードのテスト結果では明らかにGetRowsメソッドを使った方法が不利であることが分かります。大きなテーブルに対してはGetRowsメソッドを使うべきではない、というのは処理時間の面から考えても正しいことであることが分かります。ここで、なぜ大量のレコードを読み込むとパフォーマンスが大幅に低下するのかを考えてみます。その原因はパフォーマンスモニターのグラフが適確に表現していると思います。今回のテストでは、まずループを使った方法について100〜10000レコードのテーブルに対してテストを行い、続いてGetRowsメソッドを使った方法について同様のテストを行っています。これをグラフに当てはめて検証してみますと、まずループを使った方法については100→10000レコードと読み込むデータ量が増加してもメモリ上では何ら変化は見られません。ところがGetRowsメソッドについては、少量のレコードに対して実行している範疇は問題ないのですが、レコード数が5000を越えると大幅に「空きメモリ」が減少し、処理が終わると配列に占有されていたメモリが解放され「空きメモリ」が元に戻っていることが分かります。それに同期して「ページ違反」や「ページイン」も大きな挙動を見せています。これは、大量のレコード読み込みによって物理メモリが不足し、スワップファイルへの読み書きつまりディスクへのアクセスが発生していることを示しています。当然メモリ上だけの処理に比べてディスクアクセスを伴う処理では大幅にパフォーマンスが低下します。これがGetRowsメソッドを大きなテーブルに対して使った場合の内部的な動作であり、処理時間が悪化する理由です。今回のテストは端から端までフィールドデータを読み込んで終わりですが、読み取ったデータを格納した配列に対してさまざまな計算をするのような場合にはさらにページ違反が増え処理時間が悪化することも考えられます。しかし、今回のテスト環境に限れば1000レコード程度(配列のサイズ
約400K)なら問題はないといえるかもしれませんが、一般的に全フィールドのメモリサイズも含めてどの程度のレコード数までなら問題ないかといった限界点については、そのデータベースアプリケーションを走らせるパソコンの環境(メモリ容量やハードディスクのスピード)によって大きく左右されるため、見極めるのはなかなか難しそうです。