この Access Labo ではデータベースアプリケーションの高速化についてさまざまな実験を行っていますが、『正規化』の問題はAccessだけに限らず、より高速で効率的なリレーショナルデータベースを設計する上で最も根本的に考慮すべき課題といえます。正規化とは、一口で言ってしまえば「データやディスクスペースをより効率的に扱うためのテーブル設計手法あるいはテーブル分割手法」です。例えば「商品仕入データ」というものがあるとします。このデータは「仕入日」、「商品コード」、「商品名」、「仕入数量」から構成されているとします。最終的にフォームやレポートで出力する場合にはもちろん「仕入日−商品コード−商品名−仕入数量」を1行とする表形式が分かりやすいわけですが、通常は「商品コード」と「商品名」は1対1の関係になっていて、かつデータの中にはいくつもこの組み合わせが出てくるはずです。そこで「商品仕入データ」をテーブルとして設計する際は、「仕入日・商品コード・商品名・仕入数量」の4つのフィールドから成る1つのテーブルではなく、仕入日・商品コード・仕入数量の3つのフィールドから成る「商品仕入テーブル」と、商品コード・商品名の2つのフィールドから成る「商品マスタテーブル」の2つのテーブルに分割し、これらを商品コードによって結合することによってフォームやレポートに表示するデータ形式とする、というのが正規化です。これはあまりにも簡単な説明ですが、実際、正規化の手法そのものは論理的かつ複雑なものでそれだけで1冊の解説書ができるくらいです。しかし幸いAccessには"正規化ウィザード"というのがあって、正規化されていないデータを正規化された複数のテーブルに分割してくれますので、データベースの設計を初めからあまり難しく考えなくてもいいかもしれません。
さて、正規化手法そのものの難しい話しは専門書に譲るとして、ここでは「正規化」と「逆正規化」の境界線について実験を行ってみたいと思います。正規化は、理論に則れば、第1正規化から第5正規化まで(一般的には第3正規化まで?)の手順を行うことによって最終的な形になりますが、そうやってできた正規形を正規化されていない形に戻すのが『逆正規化』です。正規化がある程度理論的(手法的)に進められるのに対して、この逆正規化はその理論と実際のデータベースの運用環境、例えば更新の頻度とか、更新より参照されることの方が多いとか、データベースシステムの特性とか、あるいはネットワークの状況とか、といったこととのギャップを埋める、つまりより現実的な形にテーブルの設計を調整していくものです。
例えば、上述の「商品仕入データ」ですが、もしも月末の〆切処理によってその月だけの仕入実績をテーブル化するとします。その時点で商品コード"0001"の商品名が"AB-0001"だったとします。しかし、その後その商品の名称がたまたま"AB-0001-X"になったとします。もしこれが上述と同様に「仕入実績テーブル」と「商品マスタテーブル」の2つから構成されているとしたら、過去の仕入実績データを呼び出した時に、商品コード"0001"の商品名はすべて"AB-0001-X"になってしまいます。現在は"AB-0001-X"であっても過去のその時点での商品名は"AB-0001"だったわけですから、これは正しい情報とはいえません。したがって、このような場合にはテーブルを分割せず、「仕入実績テーブル」上に「商品名」フィールドも設けておいた方がよいことになります。
またここで、一度作られた過去の「仕入実績テーブル」はその後変更されることがなく、かつさまざなクエリーやフォーム、レポートなどを通して複数のユーザーに頻繁に参照(=読み取りのみ)されるとします。このテーブルには1万件のレコードがあって、10人が1日に1回見るとしても
10人×1万件=10万回 のレコードアクセスになります。データ入力の場合には確かに"マスタテーブル"を持つことによって商品名を入力する手間や間違いがなくなりますが、このような場合でもテーブルを2つに分割した上でわざわざ結合した方が速いのでしょうか?。
さらに、「商品仕入テーブル」には1万件のデータがあり「商品マスタテーブル」には1千件のデータがあるとします。この場合2つのテーブルを結合して「仕入日−商品コード−商品名−仕入数量」という形式のデータを1万件すべてについて表示しようとすると、1万件の1つずつが1千件のマスタテーブルを探索することになりますので、単純に考えれば平均的には500万回の探索が行われることになります(これはマスタテーブルの1レコード目で見つかることもあれば最後のレコードで見つかることもありますので、平均をとって1万件×(1000/2)として計算したものですが、現実的にはデータ内容やディスクのキャッシュなどによって大きく変ると思います)。一方、もしマスタデータが1万件の場合にはどうでしょう?。同様の計算なら1万件×(1万/2)=5000万回の探索となります。ところが、マスタデータが1万件もあるということはほとんど「商品仕入テーブル」上にある商品コードは重複していないと考えられます。このような場合にも正規化は必要なのでしょうか?。
これらの疑問をもとに、ここでは上述の仕入日・商品コード・仕入数量の3つのフィールドから成る「商品仕入テーブル」と、商品コード・商品名の2つのフィールドから成る「商品マスタテーブル」の2つのテーブルを対象に次のようなテストパターンを用意して正規化と逆正規化の境界線を探ってみることにしました。
| 番号 | 商品仕入テーブル | 商品マスタテーブル | 同じ商品コードの 出現頻度 |
|---|---|---|---|
| 1 | 「商品名」フィールドを含む正規化されていない1万件のレコード(同じ商品コードの出現頻度の大小は実行時間には影響しないと考えます) | なし | |
| 2 | 1万件のレコード(100件のマスタデータが均等にあるものとします) | 100件のレコード | 100(1万÷100) |
| 3 | 1万件のレコード(500件のマスタデータが均等にあるものとします) | 500件のレコード | 20(1万÷500) |
| 4 | 1万件のレコード(1000件のマスタデータが均等にあるものとします) | 1000件のレコード | 10(1万÷1000) |
| 5 | 1万件のレコード(2500件のマスタデータが均等にあるものとします) | 2500件のレコード | 4(1万÷2500) |
| 6 | 1万件のレコード(5000件のマスタデータが均等にあるものとします) | 5000件のレコード | 2(1万÷5000) |
| 7 | 1万件のレコード(5000件のマスタデータのうち500件だけがあるものとします) | 5000件のレコード | 20(1万÷500) |
| 8 | 1万件のレコード(5000件のマスタデータのうち1000件だけがあるものとします) | 5000件のレコード | 10(1万÷1000) |
今回のテストでは、この8つのパターンについて次のようなコードを実行し、「商品仕入テーブル」の全レコードを選択するのに要した時間を測定・比較します。なお、テーブル名はテストパターンの番号を使って、商品仕入1・商品仕入2・・・・・・商品仕入8 というようにしています。
Dim dbs As Database
Dim rst As Recordset
Dim strSQL As String
Dim intTestNum As Integer
Dim varDummy As Variant
Set dbs = CurrentDb
ts_Watch "テスト開始", True
'テスト1
strSQL = "商品仕入1"
intTestNum = 1
GoSub RecReadLoop
'テスト2〜8
For intTestNum = 2 To 8
strSQL = "SELECT 商品仕入" & intTestNum & ".商品コード,商品名,仕入数量" & _
" FROM 商品仕入" & intTestNum & _
" INNER JOIN 商品マスタ" & intTestNum & _
" ON 商品仕入" & intTestNum & ".商品コード=商品マスタ" & intTestNum & ".商品コード"
GoSub RecReadLoop
Next intTestNum
Exit Sub
RecReadLoop:
Set rst = dbs.OpenRecordset(strSQL)
ts_Watch "テスト" & intTestNum & "Recordsetオープン"
With rst
Do Until .EOF
varDummy = !商品コード
varDummy = !商品名
varDummy = !仕入数量
.MoveNext
Loop
.Close
End With
ts_Watch "テスト" & intTestNum & "読み込み"
Return
さらに、正規化によってテーブルを分割することには、リレーションシップによって「連鎖更新」や「連鎖削除」を使えるというメリットもあります。そこで2つのテーブルにリレーションシップを設定し、連鎖更新するようにした上でマスタテーブル上のすべてのレコードの「商品コード」フィールドを更新してみます。これによって2〜8のパターンについては商品仕入テーブル側の商品コードも自動的に更新されますが、1については商品仕入テーブルの全レコードを直接更新する必要があります。
Dim dbs As Database
Dim rst As Recordset
Dim strTblName As String
Dim intTestNum As Integer
Set dbs = CurrentDb
ts_Watch "テスト開始", True
'テスト1
'これはすべてのデータテーブルのレコードを更新する
strTblName = "商品仕入1"
intTestNum = 1
GoSub RecUpdateLoop
'テスト2〜8
'これはすべてのマスタ側のテーブルのレコードを更新する
For intTestNum = 2 To 8
strTblName = "商品マスタ" & intTestNum & ""
GoSub RecUpdateLoop
Next intTestNum
Exit Sub
RecUpdateLoop:
Set rst = dbs.OpenRecordset(strTblName)
ts_Watch "テスト" & intTestNum & "Recordsetオープン"
With rst
Do Until .EOF
.Edit
!商品コード = !商品コード + 10000
.Update
.MoveNext
Loop
.Close
End With
ts_Watch "テスト" & intTestNum & "更新"
Return
そして、テスト結果はつぎのようなものになりました。なお時間の単位は"秒"です。
テスト番号 同じ商品コード
の出現頻度レコード選択の場合 マスタ更新の場合 Rstオープン レコード読込 Rstオープン レコード更新 1 − 0.06 2.03 0.08 14.25 2 100 0.08 5.71 0.05 4.47 3 20 0.05 6.18 0.00 8.68 4 10 0.05 6.38 0.05 14.56 5 4 0.05 6.59 0.06 29.46 6 2 0.05 7.06 0.05 49.71 7 20 0.05 6.42 0.05 25.32 8 10 0.05 6.68 0.00 27.60
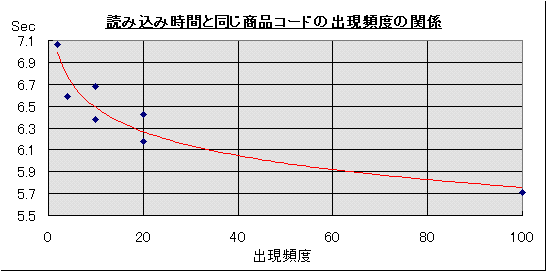
結果より、レコードを読み込むだけの場合には明らかに商品名フィールドも含めた正規化されていないテーブルの方が速いことが分かります。このことから上述の「商品仕入データ」の月末〆切処理のように、データ更新がなく参照だけのテーブルの場合には正規化せずに単独のテーブルにすべてのデータを含めた方がよいことが分かります。一方、正規化によって複数のテーブルに分割されたものについては、マスタデータが少なくかつ1つのマスタのキーが頻繁に使われるような場合(上の結果では同じ商品コードの出現頻度の高いもの)の方が処理が速いことが分かります。これについては、正規化する・しないの判断の基準は明確には分かりませんが、極端にマスタデータの出現頻度が低いデータテーブルについては正規化しないことも検討した方がよいことを示していると思います。なお、今回のテストの中でRecordsetを開く時間を別に測定したのは、テーブルが複数に分かれていることによって、それを結合するための時間がRecordsetを開くのに要する時間に影響を与えるのではないかと予想したからなのですが、それはあまり関係なかったようです。このことは、結合とはいっても最初にまとめて結合されるのではなく、1レコードを読み込むごとにマスタからレコードが探索されて結合されていると考えてよいでしょう。
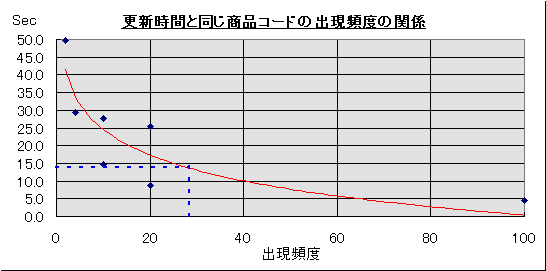
一方、更新の場合にもおおむねマスタデータの出現頻度が高い方が高速であることが分かります。ただ、レコードを読み込む場合のテスト結果と大きく異なるのは、正規化されていないテーブルを更新した方が明らかに速いあるいは遅いというのではなく、正規化した方がよい場合としない方がよい場合との境界線があるという点です。具体的にはグラフ上に示した「出現頻度≒30」がこれにあたります。これより出現頻度が高いものは正規化した方がよい、つまり、リレーションシップの「連鎖更新」を利用した方が速いということがいえると思います。逆にこれより出現頻度が低いものについては正規化せず連鎖更新も設定せず、データテーブルに対して更新をかけた方がよいといえます。ただし、今回はマスタデータのすべてのレコードを一括更新するという処理なので、特定の条件に合う部分的なレコードだけを更新するような場合にはまた違った結果になる可能性もあります。したがって「出現頻度≒30」は常にあてはまる定数としてそのまま適用するのではなく、あくまでも「正規化した方がよいときとしない方がよいときには何らかの境界線がある」ということを頭に入れておけばいいと思います。