データベースのパフォーマンスを最適化しようとする時に、正規化などによってテーブル構造を見直したり、テーブルのインデックスの付け方に目を向けることは重要である、というのをよく見聞きします。そこで、ここでは実際にテーブルにインデックスを付けた場合と付けない場合でどのくらいの時間的違いがあるのかを検証してみたいと思います。
テストの内容としては、6種類のテーブルに対して、それぞれ5万件のレコード追加と一部のレコードの読み込み、全レコードの更新、さらに全レコードの削除をVBAを使って行うものです。レコードの読み込みではインデックスの設定されているフィールドに対してWHERE条件を付けて5千件のレコードを抽出するようにします。ここで6種類のテーブルとは、フィールド数が2つのものと50ケのものそれぞれについて「重複なしのインデックス」、「重複ありのインデックス」、「インデックスなし」を設定したものです。フィールド数の違いを設けたのは「インデックスがある場合にはまずインデックス領域を検索して見つかったらそれに対応するデータ領域を読みに行き、無い場合にはいきなりデータ領域を検索しに行く」という内部動作になっているのではないかという推測に基づくものです。もしそうであれば、データ領域の幅が広い(=フィールド数が多い)か狭いかといったことが処理時間に影響を与えるのではないかと考えたのです。これは昔(今でもあるのでしょうが)dBASEが、インデックスファイルとデータファイルの2つの物理的なファイルによって構成されていたことを思い出し、Accessでも物理的には1つのMDBでも内部的には2つの領域を持っているのではないかという想像から考えついたものです(ただしこの辺はリレーショナルデータベースの内部構造について勉強不足で定かではありません)。
テストコードは次のようなものです。
Dim dbs As Database
Dim rst As Recordset
Dim lngCnt As Long
Dim strName As String
Dim ilngLoop As Long
Dim itblCount As Integer
Const cRecMax As Long = 50000
Dim astrTableName(6)
astrTableName(1) = "tblFld2重複なしIndex"
astrTableName(2) = "tblFld2重複ありIndex"
astrTableName(3) = "tblFld2Indexなし"
astrTableName(4) = "tblFld50重複なしIndex"
astrTableName(5) = "tblFld50重複ありIndex"
astrTableName(6) = "tblFld50Indexなし"
Set dbs = CurrentDb
ts_Watch "開始", True
For itblCount = 1 To 6
Set rst = dbs.OpenRecordset(astrTableName(itblCount))
GoSub AddSub
ts_Watch "テスト" & (itblCount - 1) * 4 + 1
Set rst = dbs.OpenRecordset("SELECT * FROM " &
astrTableName(itblCount) & _
" WHERE (Count mod 10=0)")
GoSub SelectSub
ts_Watch "テスト" & (itblCount - 1) * 4 + 2
Set rst = dbs.OpenRecordset(astrTableName(itblCount))
GoSub EditSub
ts_Watch "テスト" & (itblCount - 1) * 4 + 3
Set rst = dbs.OpenRecordset(astrTableName(itblCount))
GoSub DeleteSub
ts_Watch "テスト" & (itblCount - 1) * 4 + 4
Next itblCount
Exit Sub
※AddSubなどのサブルーチンについては、#04とほとんど同じなので割愛します。
そして、テスト結果はつぎのようなものになりました。 なお時間の単位は"秒"です。
フィールド数 インデックス 追加 選択 更新 削除 2 あり(重複なし) 44.7 4.4 35.4 24.8 あり(重複あり) 45.8 5.1 35.9 27.1 なし 32.6 3.4 35.9 15.2 50 あり(重複なし) 66.7 4.8 42.8 29.0 あり(重複あり) 67.3 4.9 42.8 28.9 なし 57.8 5.5 44.0 19.6
テスト結果のデータ数が多いので、分かりやすくするためにグラフ化してみました。このグラフからインデックスの有無の影響を分析してみましょう。
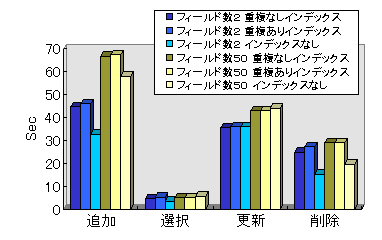
- レコードを追加・削除する場合はインデックスが無い方が速い。これは言うまでもなく、レコード追加の際にはデータを書き込むだけでなく、インデックスの再編成が行われるためです。このインデックスの再編成は当然レコードが削除された時にも必要となるので「削除」でも同様にインデックスが無い方が速くなります。
- レコードを更新する場合はあまり大差はない。上記の理屈でいえば、更新の場合はインデックスの再編成は必要ないのでその差は現れないことになります。ただ、コードを見れば分かるようにすべてのレコードを順番に一気に更新する処理なので、あるレコードを検索してから更新するような場合にはまた別の結果になることも忘れないで下さい。
- レコードの選択については、グラフではインデックスの効果はほとんど無いように見受けられますが、一概に決め付けてはいけないようです。レコード選択の測定値が他に比べて小さいために見過ごしがちですが、よくみるとフィールド数が2つの時と50ケの時とでその傾向が違うことが分かります。フィールド数が2つの時には意外にも重複ありのインデックスが一番時間がかかっているのですが、フィールド数が多くなるとインデックスなしがもっとも時間がかかっています。これは最初で説明したデータ領域の幅のせいと考えていいでしょう。ちなみに50ケあるフィールドでもフィールドの位置によってその時間が異なる、つまり後ろのフィールドにアクセスするほどインデックスが無い場合の時間が大きくなることも今回のテストの過程で確認されております。ここではあまり差が出ませんでしたが、今回のテストはあくまでも1つのテーブルだけを対象としていますので、もしこれがクエリーならばテーブル間の結合に際しさらにインデックスの有無が影響してくることも考えられますし、もっと複雑なWHERE条件の場合にも異なる結果が予想されますので、実際のテーブル設計では個々の状況ごとに試行錯誤していくことが必要と思われます。